第十四章 云原生架構設計理論與實踐 數據處理服務的核心構建與演進
在當今數據驅動的時代,數據處理已成為企業數字化轉型的核心引擎。云原生架構以其彈性、可擴展性和敏捷性,為數據處理服務的設計與實踐提供了全新的范式。本章將深入探討云原生架構下數據處理服務的設計原則、關鍵技術組件及其實踐路徑。
一、云原生數據處理服務的設計原則
云原生數據處理服務的設計遵循一系列核心原則,確保其在動態、分布式的云環境中高效運行:
- 彈性與可擴展性:服務應能根據數據負載自動伸縮,利用容器化技術(如Docker)和編排系統(如Kubernetes)實現資源的動態分配,避免性能瓶頸與資源浪費。
- 松耦合與微服務化:將復雜的數據處理流程拆分為獨立的微服務,每個服務專注于單一功能(如數據攝取、清洗、分析或存儲),通過API進行通信,提升系統的可維護性與部署靈活性。
- 事件驅動與流式處理:采用事件驅動架構(EDA)和流處理框架(如Apache Kafka、Flink),支持實時或近實時的數據處理,滿足對低延遲洞察的迫切需求。
- 可觀測性與韌性:集成日志記錄、指標監控和分布式追蹤(如Prometheus、Jaeger),實現服務運行狀態的透明可視;通過重試、熔斷和降級等模式增強系統容錯能力。
- 聲明式配置與自動化:使用基礎設施即代碼(IaC)工具(如Terraform)和聲明式配置管理,確保數據處理管道的可重復部署與一致性,減少人工干預。
二、關鍵技術組件與架構模式
一個典型的云原生數據處理服務棧通常包含以下層次與組件:
- 數據攝取層:負責從多樣化源(數據庫、IoT設備、日志文件等)收集數據,常借助Change Data Capture(CDC)工具或消息隊列實現高效、低侵入的數據同步。
- 處理與計算層:這是核心層,可進一步劃分為批處理(使用Spark、AWS Glue等)和流處理(使用Kafka Streams、Google Dataflow等)。無服務器計算(如AWS Lambda)也日益流行,用于事件觸發的輕量級處理任務。
- 存儲層:采用多模型存儲策略,包括對象存儲(如Amazon S3)用于原始數據湖,NoSQL數據庫(如Cassandra)處理非結構化數據,以及云原生數據倉庫(如Snowflake、BigQuery)支持復雜分析。
- 服務與API層:通過RESTful或GraphQL API將處理后的數據暴露給下游應用,同時確保安全認證與訪問控制。
- 編排與調度層:利用Kubernetes Jobs、Argo Workflows或Apache Airflow等工具,編排復雜的數據管道,管理任務依賴與執行周期。
架構模式上,數據網格(Data Mesh) 作為一種新興的分布式架構理念,強調將數據作為產品,由領域團隊自主管理其數據管道與服務,正成為大規模云原生數據處理的重要演進方向。
三、實踐路徑與挑戰
在實踐中,構建云原生數據處理服務需循序漸進:
- 評估與規劃:明確業務需求、數據規模與處理延遲要求,選擇合適的技術棧與服務模型(如自建K8s集群或采用托管服務)。
- 漸進式遷移:對于遺留系統,可采用Strangler Fig模式,逐步將功能遷移至云原生服務,而非一次性重構。
- DevOps與DataOps融合:將數據處理管道納入CI/CD流程,實現數據代碼的版本控制、自動化測試與持續部署,提升數據質量與交付速度。
- 安全與治理:實施端到端的數據加密(傳輸中與靜態)、基于角色的訪問控制(RBAC),并建立數據血緣追蹤與合規性審計機制。
面臨的挑戰包括:跨云/混合云環境的數據一致性、處理成本優化(避免云資源浪費)、以及確保在高度分布式系統中數據的準確性與時效性。
四、未來展望
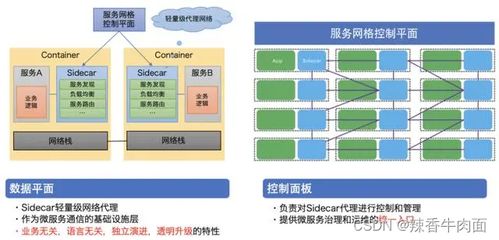
隨著邊緣計算、AI/ML的深度融合,云原生數據處理服務正朝著智能化與泛在化發展。服務網格(如Istio)將加強服務間通信的管理,而Serverless與FaaS的演進將進一步抽象基礎設施復雜度,讓開發者更專注于數據處理邏輯本身。
云原生架構為數據處理服務帶來了前所未有的靈活性與效率。通過遵循其設計原則,合理選用技術組件,并持續迭代實踐,組織能夠構建出響應迅速、穩健可靠的數據處理能力,從而在數據洪流中捕獲核心價值,驅動創新與增長。
如若轉載,請注明出處:http://www.xgnt.com.cn/product/74.html
更新時間:2026-02-13 07:40:11